Audio Engineers will know this subject well. Grounding has many purposes, including electrical safety, lightning protection, RF shielding, and audio noise mitigation. Although all types of grounds are related in that they are designed to conduct stray electrons to a safe place to be dissipated, the designs of each type are somewhat different. What might be an excellent audio ground may not be the best lightning ground and vice versa. Sometimes good audio grounds can lead to stray RF pickup.
The basic ground loop looks something like this:
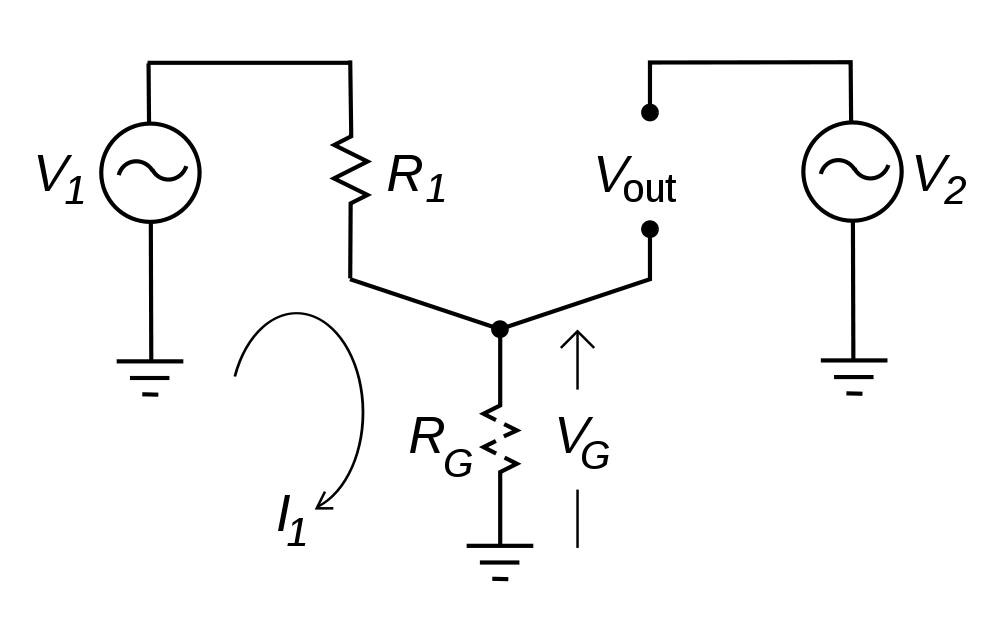
Where RG should equal zero, in this representation it is some other resistance. This causes a different potential on the circuit (V1), which in turn causes current to flow (I1). It is that unexpected flow of current that creates the problems, causing voltage (V2) to be induced on another part of the circuit. In cabling applications, this will result in a loud, usually 60-cycle hum impressed on the audio or video being transmitted through the cable.
The resistance can come from something as mundane as the length of the conductor going to ground. This can often happen when using shielded audio wire in installations when the connected equipment is already grounded through the electrical plug.
There are two proven methods for eliminating ground loops, both of which are best implemented in the design phase of construction (aren’t most things).
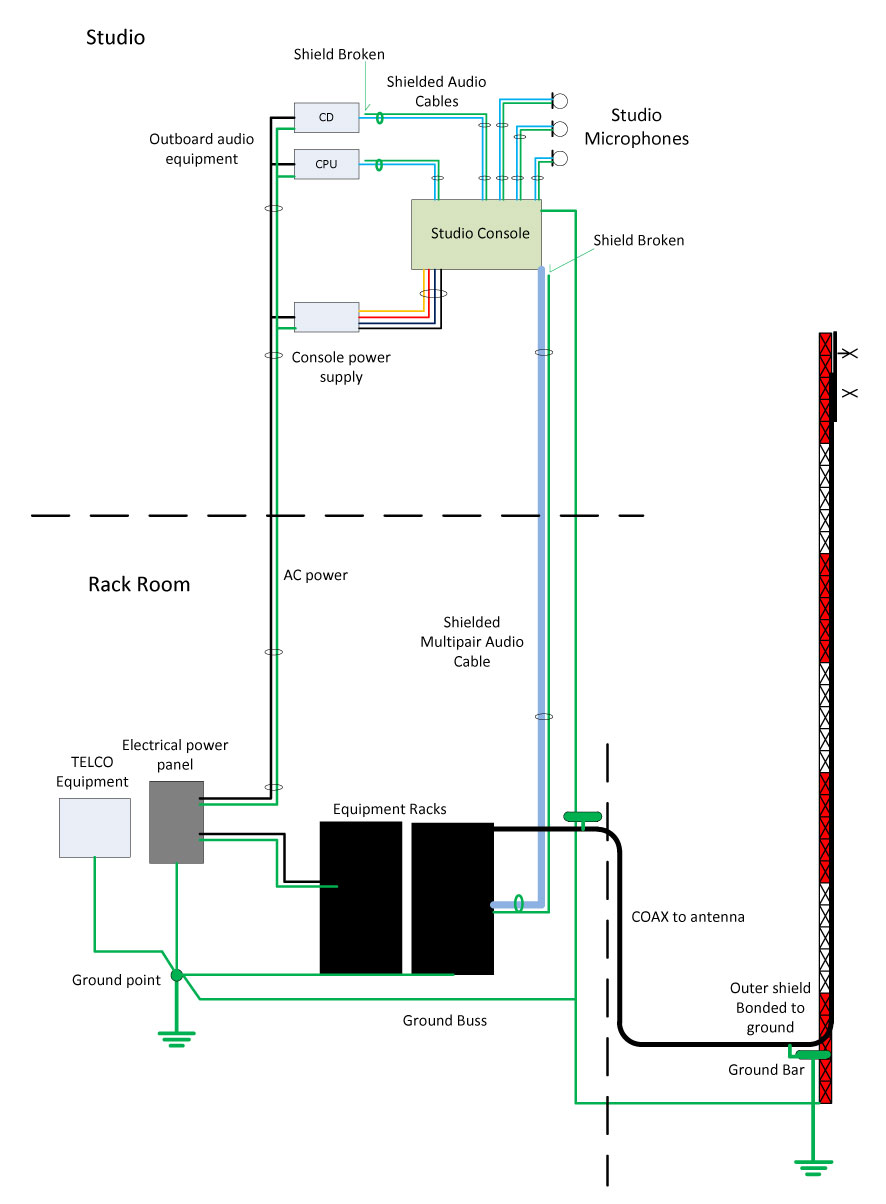
The first is a single ground point topology, also known as a common point or star grounding system. A common ground system consists of one grounding point or buss bonded together so that it has the same potential. All grounded equipment is then connected to that point creating a single path to ground. All modern electrical equipment has a path to ground via the third prong of its electrical cord. Problems can or will occur when audio equipment is plugged into separate AC circuits, grounded via the electrical plug, and then tied together via an audio ground. The longer the separate grounding paths, the more severe 60 cycle (or some harmonic thereof) hum can result.
To eliminate this problem, the shields should be broken at one end of the audio cable. Never cut the third prong off of an electric cord, which can create another problem called electrocution. Given the choice between a ground loop and electrocution, I’d stay away from electrocution, mine or somebody else’s.
For installations in high RF fields, the open shield or ground drain can act like an antenna. In those situations, the open end can be bypassed to ground using a 0.01 uf ceramic disk capacitor. Electrically, this will look like an open at DC or 60 cycles, but allow stray RF a path to ground. This problem can be a common occurrence when studios are co-located with transmitters.
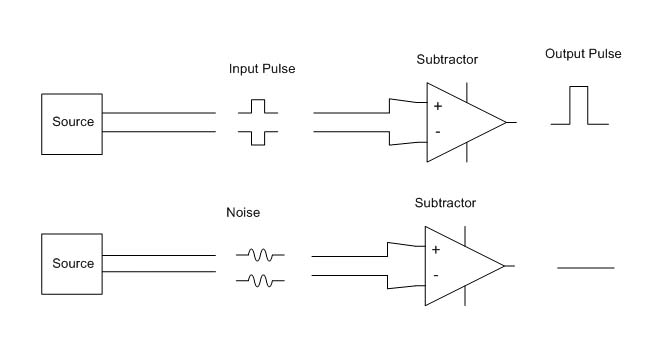
The second is by using balanced audio or differential signals as much as possible. This poses a problem for those stations that use consumer grade components, especially in high RF fields. For shorter cable lengths, two or three feet, it is usually not a problem. Anything beyond that, however, and trouble awaits.
It is relatively easy and inexpensive to convert audio from unbalanced to balanced. As much as possible, equipment and sound cards that have balanced audio inputs and outputs should be used. In the end, it will simply sound better to use higher quality equipment. Also, longer cable runs need to be properly terminated at both ends.
Installing equipment using good engineering principles and techniques will eliminate these problems before they start.




